
DuckDB: Primer on the subject and fascinating highlights
Read the full article here
What’s DuckDB?
The original purpose behind DuckDB’s creation was to empower analytical query workloads and facilitate online analytical processing (OLAP) tasks. Essentially, it falls into the realm of relational database management systems (RDBMS), fully equipped with support for Structured Query Language (SQL).
DuckDB strives to deliver a swift, feature-rich, and user-friendly database management system for analytical tasks. It capitalizes on technical breakthroughs, emphasizes simplicity, and fosters open collaboration to create a robust and mature database solution.

POLARS: A Swift and Powerful DataFrame Library for Analytical Tasks
Read the full article here
Essential to data engineering and data science are the tasks of data manipulation and analysis. Pandas has long been the staple library for these tasks in Python, but it can falter when handling large datasets due to performance issues. This challenge has paved the way for new innovations. Enter Polars, a rapid DataFrame library developed in Rust, celebrated for its impressive speed and efficiency. This blog post will cover what Polars is, the reasons behind its rising popularity, and how you can begin using it for your data projects.
Press enter or click to view image in full size
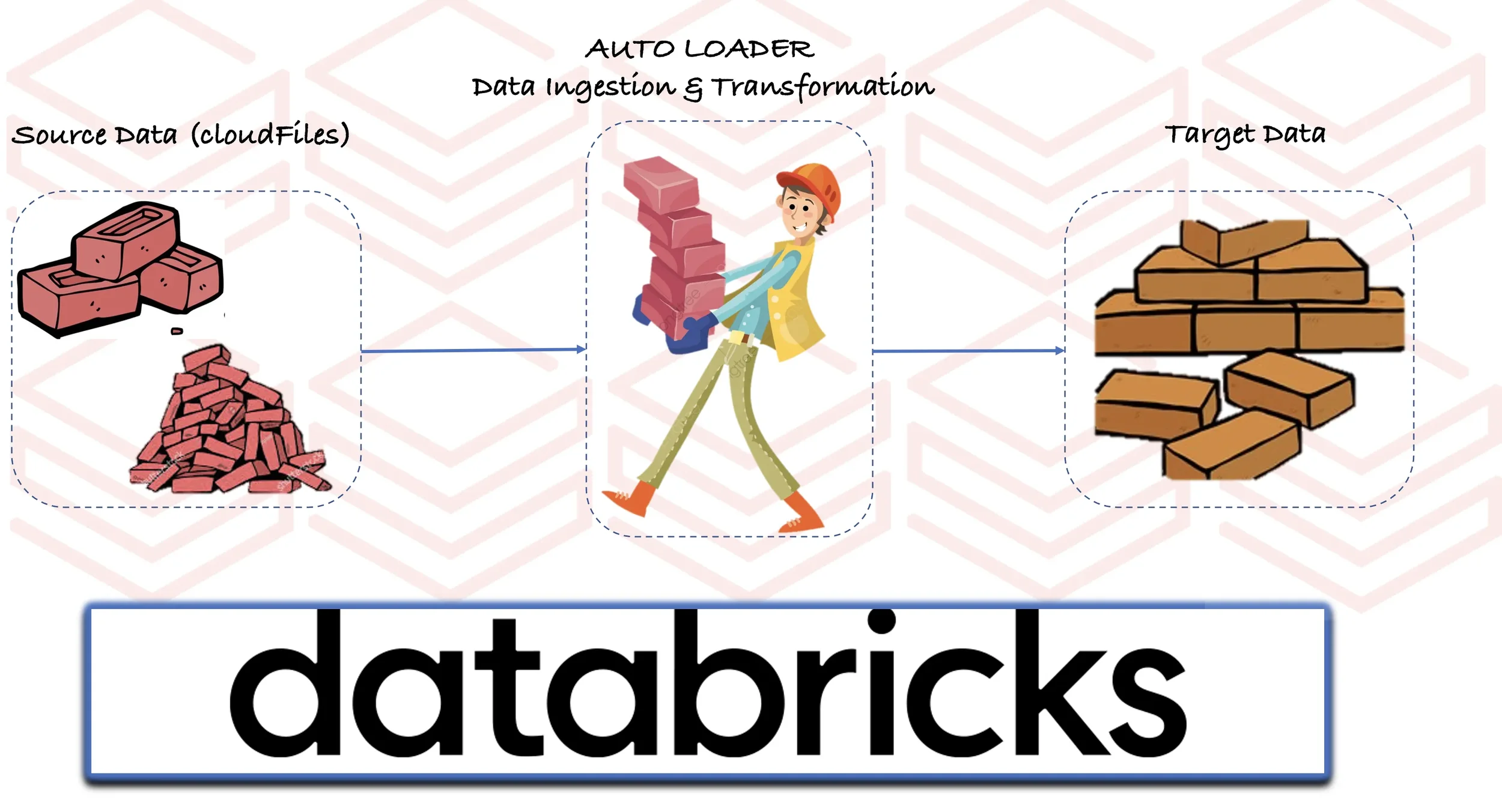
Databricks AutoLoader : Enhance ETL by simplifying Data Ingestion Process
It all begins with an idea.
Read the full article here
Introduction:
Before we start deep diving on AutoLoader, let us focus on the existing data engineering issues in ingestion process that fits into one of the below categories:
High Latency due to batch processing: Though data is landing at regular intervals for every few minutes, most of the cases a batch job can be scheduled to process files for every one hour. This increases latency (and lengthens SLA) and adds huge workload, since every batch needs to process huge chunks of files.
Processing too small files in stream processing: A streaming job that is continuously monitoring for source files and processing small chunks of data results in writing too small files in target system which introduces new set of issues for downstream consumers.
Missing Input Files: Files getting created before the start of batch processing and completed after the start of batch processing might get missed during processing. For example, consider a hourly scheduled job and an input file getting created 5 minutes before start of the job and ends 2 minutes after start of the job. This file will get picked only during the next batch and will increase SLA by one hour.
Cloud Rate Limit Issue: The naive file-based streaming source identifies new files in cloud by recursively traversing through the cloud buckets/folders to differentiate new files between old files. Both cost and latency can add up quickly as more and more files get added to a directory due to repeated listing of files. We might also get into Rate Limit Issue set up by cloud service provider. (For example, S3 throws exception whenever number of requests made to S3 has crossed a particular limit)

Google Spanner: The Database That Scales Globally with Strong Consistency
Google Spanner: The Database That Scales Globally with Strong Consistency
Read the full article here
In the modern data engineering landscape, companies require applications that can scale globally without compromising on performance and reliability. As user demands grow, databases must process vast amounts of data, deliver low-latency access, and ensure consistency. While there are several databases with distinctive features available today, Google Spanner stands out as a truly unique option. It is a fully managed, scalable relational database that combines global distribution with strong consistency, making it a powerful choice for businesses.
GOOGLE SPANNER
GOOGLE SPANNER: It is a distributed relational database service developed by Google. It is part of Google Cloud and combines the benefits of NoSQL scalability with the strong consistency and ACID properties of traditional relational databases. What sets Spanner apart from other databases is its ability to horizontally scale across data centers while still providing a global namespace and maintaining consistency across the globe.

Essential Considerations for Data Engineers When Selecting a NoSQL Database
It all begins with an idea.
Read the full article here
In the realm of modern data engineering, the choices abound, and the stakes are high. Data engineers are the architects of the digital age, tasked with crafting the data foundations upon which businesses build their futures. In this era of big data, rapid scalability, and diverse data types, the selection of the right database is akin to choosing the cornerstone of a magnificent structure — it’s fundamental to success.
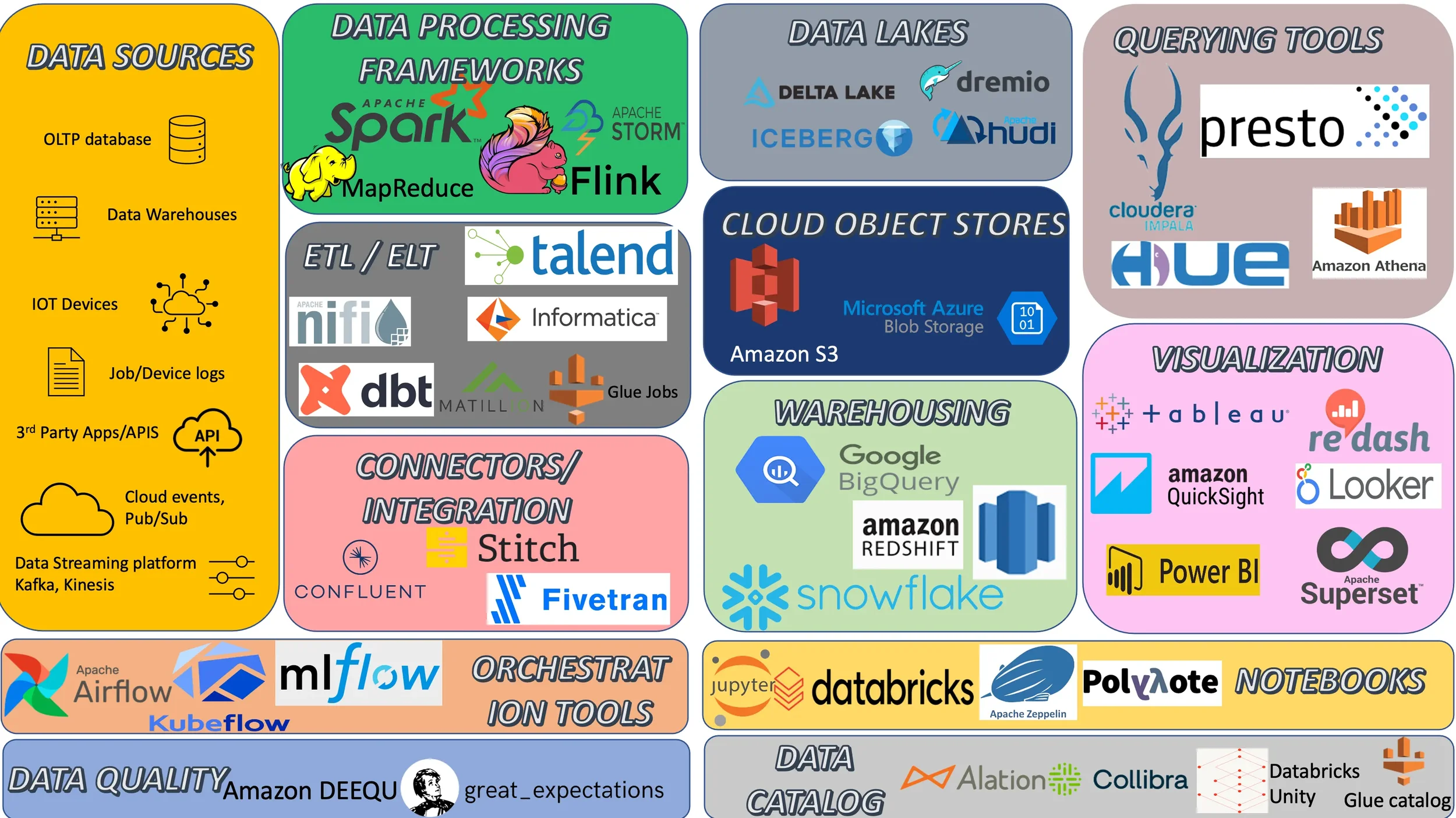
2022 : Modern Data Stack
It all begins with an idea.
Read the full article here
You might have seen multiple posts around this subject as time keeps evolving and bringing changes into tech stack, however this includes recent discovery in data processing frameworks, visualization tools, ETL tools, Development notebooks, Data catalog..etc
Over the time, we might have come across different terms like ETL, ELT, Reverse ETL. When it comes to database, jargon words that changed over time includes OLTP, OLAP, Big Data, Data Lake and Data Lakehouse..etc.
One of the highlighting difference between modern data stack and a legacy data stack is that modern data stack is cloud hosted and expects very less effort from users.
This post covers the list of tech stack in the picture in brief. It mostly covers the list of tools that I have come across in my experience. Let me know in comments section for any tools/frameworks that has been missed out.